Useful links
Contact: Harald Carlens on Whova
ICML 2024 wrapped up after the second day of workshops — following three days of the main conference, a day of tutorials, and an expo day.

As always, alongside the official conference programme there were countless meetups, happy hours, dinners, lunches, and other events that happened throughout the week.

As everyone heads home, there will be things from the week sticking in their heads. Based on the polls on the conference app, there was one topic this week more contentious than everything else. The most active community poll — by quite some margin — was titled “Are you freezing?”, in the group “Petition to turn down the air conditioning”.

Opinion was… divided! Over 400 people expressed their views through the poll. There was some speculation as to geographical divides over air con preferences.
All this seemed like an elaborate setup for Jan Ebert, who just left two words in the air con chat: “Icy ML”.
There were many great workshops on Saturday, just as there were on Friday. While the venue as a whole felt a little less busy, all the workshops I saw were very well-attended.
Based on the numbers in the conference app, the most popular workshops on Saturday were Geometry-grounded Representation Learning and Generative Modelling (workshop site) and Theoretical Foundations of Foundation Models (workshop site).
The most popular workshops on Friday had been the AI for Science (workshop site) and ML For Life and Material Science (workshop site) workshops.
At various times, people were no longer allowed into the Mechanistic Interpretability workshop or the LLMs and Cognition workshop due to the rooms being too busy.

There were so many great papers and posters! To pick just one, I spoke to the authors of the “Code Agents are SOTA Software Testers” paper. They took SWE-Bench (arxiv), a dataset designed for testing code fixing ability, and used it to build SWT-Bench — a benchmark for test generation.

The original SWE-Bench collected GitHub issues, along with the code patches applied to fix them. SWT-Bench flips this around, requiring a test to be written for a given GitHub issue. The proposed test is then validated: correct tests should fail on the pre-patch codebase, and pass on the codebase with the patch applied.
The Data-centric Machine Learning Research (DMLR) workshop this year focused on the theme of “Datasets for Foundation Models” (ICML link / Workshop website).
Lucas Beyer’s talk on “Vision in the age of LLMs — a data-centric perspective” made the case for language as a universal API.
He described the shift that had happened in computer vision modelling in recent years. The “classic” way to do image classification is to take an image as input, and output a probability distribution over a pre-specified set of labels (e.g. hotdog/not hotdog, or the 1,000 classes in ImageNet).
More recently, with models like OpenAI’s CLIP (arxiv) and Google DeepMind’s
SigLIP (arxiv) models — the latter of which Beyer contributed to — can
be presented with an image and a set of natural-language phrases, effectively allowing them to be used as a zero-shot
classifier based on which phrase is “most likely” to accompany the image.

Lucas showed how this approach can be extended further. Models like PaliGemma (arxiv / Google blog), for which he led the development, take an (image, text) pair and output text. With sufficient pre-training and some preference tuning using reinforcement learning, general models like PaliGemma can be applied to many tasks which previously required specific model architectures with their own from-scratch training.
Some examples of tasks include visual question answering (input image + text question, output text answer), image object detection/segmentation (output coordinates of bounding boxes in text), and image captioning.
Beyer’s talk was followed by a brief talk from Angéline Pouget, describing the No Filter paper that Pouget, Beyer, and others published earlier this year (arxiv).
Pouget’s work pointed out the that the common technique of filtering training data to include only English-language image-text tuples harms the trained model’s performance on many tasks. For example, models trained on filtered data mis-identifying the Milad Tower in Iran as the CN Tower in Canada.

This effect is exacerbated by the incentives to perform well on popular Western-centric ImageNet and COCO datasets, though Pouget’s work showed that pretraining on global data before fine-tuning on English-only content can improve global performance without sacrificing performance on those benchmarks.
Despite that, her paper notes that there remain some trade-offs between optimising for English-only performance and performance on more culturally diverse data, highlighting the insufficiency of benchmarks like ImageNet for global use.
An anecdote from Beyer’s earlier talk shed some light on how these datasets came to be the way they are — he explained that when the popular COCO (common objects in context) dataset was being created, the creators (based in the US) asked their children for a list of common objects that came to mind. The 80 object classes include “frisbee”, “snowboard”, “skis”, “hot dog”, “pizza”, and both “baseball glove” and “baseball bat”.
For more on these talks and others in the DMLR workshop on datasets for foundation models, visit the workshop site.
The afternoon session of the AI for Math workshop featured two invited talks, a panel discussion, a poster session, the workshop’s best paper award, and presentations from challenge winners.
The workshop’s best paper award was given to PutnamBench, which was presented by George Tsoukalas from UT Austin.
Tsoukalas gave a brief overview of existing benchmarks, and introduced PutnamBench as a “next-gen olympiad-style benchmark”. PutnamBench has several nice properties:

The problems in PutnamBench are sourced from the William Lowell Putnam Mathematical Competition for undergraduate students in the US and Canada, which has run annually since 1938. Previous Putnam Fellows (top 5 finishers) include Richard Feynman and three Fields medalists.
For more on PutnamBench, see the paper website, which includes a leaderboard listing various methods’ performance.
The honorable mention award was given to “Progress or Regress? Self-Improvement Reversal in Post-training” and presented virtually by Ting Wu from Fudan University.
The paper introduces the concept of “Self-improvement Reversal” which the authors define as a phenomenon that occurs during iterative post-training, when improvements in pass@1 accuracy come along with a decline in broader capabilities like output diversity and out-of-distribution generalisation.
For more information, see the paper website.
Yilun Zhou gave a talk on evaluating LLMs’ mathematical reasoning skills.
LLMs are getting better and their math benchmark performances are saturating — perhaps not surprising given the limited difficulty of the problems presented by many of them. Zhou walked through two examples in the MATH benchmark dataset, and introduced the CHAMP dataset created by him and co-authors Yujun Mao and Yoon Kim.

The CHAMP dataset contains “challenging high school competition-level math problems”, alongside hints for each problem and key concepts relevant to each problem — allowing for models to be evaluated on how well they are able to incorporate additional relevant information into their solutions.
More info on CHAMP, including a helpful dataset explorer tool, can be found on the CHAMP website.
Anima Anandkumar gave a brief remote talk covering her and collaborators’ work on tools including LeanDojo, which provides an LLM assistant in a Copilot model to aid in formal proof search. The Lean Copilot can be integrated in a user’s IDE, run locally or on the cloud, and provide suggested tactics/premises at any proof step.
")
One key difference between Lean Copilot and LLM-based programming assistants is that suggestions in Lean Copilot have already been vetted for correctness — a benefit of the formal and stepwise nature of Lean in comparison with programming in languages like Python.
For more information, see the LeanDojo website.
The workshop ended with a panel discussion followed by a poster session.
The organisers gathered answers to seven questions from the speakers before the workshop — on topics including the relative promise of different research paths and expected timelines for various milestones.

One question asked about the expected timeline for an AI system to obtain an IMO gold medal. After yesterday’s announcement from Google DeepMind showing a system that had narrowly missed out on a gold medal, almost all panelists agreed that this would be achieved at the next IMO, in 2025. The one holdout expected 2026, and cited the difficulty of formalising the combinatorics problems.

Panelists’ differences in opinion tended to be slight, and more due to nuances between “in principle” and “in practice” considerations. For example, most panelists seemed to believe that text-only models were sufficient (in principle) for achieving superhuman mathematical reasoning performance, but that in practice multi-modal models might allow us to get there more quickly.
The panel was followed by a brief poster session, cut short by our eviction as the venue closed.

Throughout the workshop, it was clear that AI for Mathematics is a field where significant progress is being made, and will continue to be made at a rapid pace in the near future.

This was the first AI for Math workshop at ICML, and hopefully the first of many!
This post gave an overview of the afternoon session. See the earlier post for the morning session. Another post will follow, describing the workshop challenges and winning solutions.
For more details on the speakers, challenges, and awards, visit the workshop website.
The ICML 2024 AI for Math workshop hosted three challenge tracks. In total, the challenge tracks had 184 participants and 1,495 submissions.
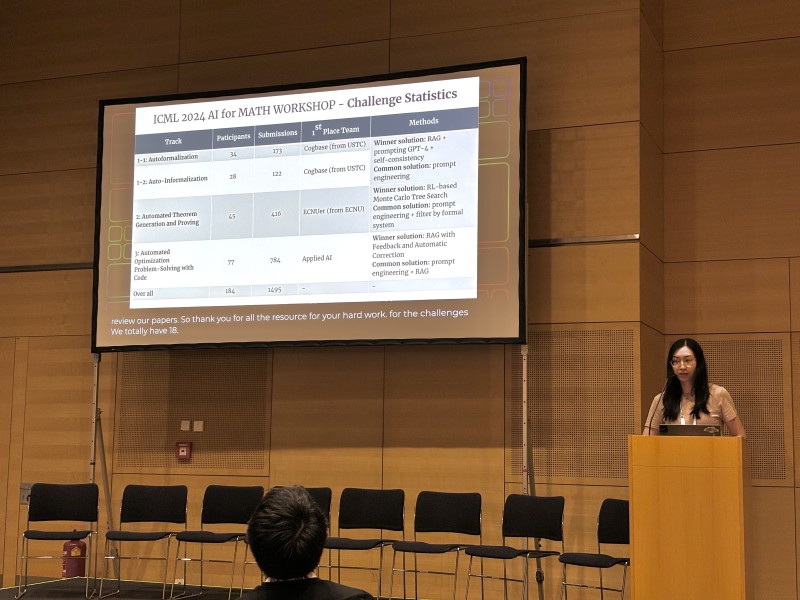
More information on each of the challenge tracks can be found on the workshop site.
Track 1 tested auto-formalisation and auto-informalisation of proofs, into/from Lean 3.
The data for the competition included problems from the public MUSTARD dataset (arxiv), as well as some additional (unseen) annotated IMO examples for the test set.

Zhiyuan Ma from the winning Cogbase team from USTC presented the winning solution, which involved using retrieval-augmented-generation (RAG) using GPT-4, coupled with a critic agent which judged candidate solutions on accuracy and semantic similarity to the problem.
Track 2 involved automated theorem generation and proving. Participants were provided with a set of axioms and symbols in Metamath from the ATG dataset (arxiv), and tasked to generate reusable theorems which reduce proof steps.

Lei Wang from the ECNU team presented their winning solution, which was based on monte carlo tree search through selection, expansion, and backpropagation steps.
Track three was an operations research task, and involved taking an optimisation problem stated in natural language, generating code to solve the problem (solver libraries allowed), and outputting a numerical solution. Each problem was designed to have a unique optimal solution, making evaluation easy.
This track was won by a corporate team from Spindox, and presented by Francesco Romito and Raffaele Mariosa.

Raffaele reviewed the team’s approach, as well as how it evolved over time — starting by trying the open-source Zephyr-7B model, before replacing it with GPT-3.5 Turbo (improvement), then replacing it with GPT-4 Turbo (improvement), trying GPT-3.5 Turbo with fine-tuning (regression), and in the end focusing on GPT-4 Turbo with a few pipeline enhancements.
Their pipeline enhancements involved prompt engineering for specific situations, iterating on solution code through generation-correction loops taking into account error information returned by the Python interpreter, sampling multiple temperature values, and then choosing from among multiple candidates using majority-voting.
The code for their solution is available in their GitHub repository.
The ICML 2024 AI for Math(s) workshop (ICML page / workshop website) was auspiciously timed, starting the morning after Google DeepMind announced their IMO silver-medal-level systems, AlphaProof and AlphaGeometry 2 (Google DeepMind blog).

There were many great talks and posters in this workshop. This post covers the talks up to the lunch break, and will be followed by posts describing the competitions and afternoon talks.
M. Pawan Kumar presented the FunSearch system, which has discovered novel results to difficult problems by searching in function space — through manipulating Python programs — as opposed to searching in solution space directly. An LLM is used to guide the evolutionary search process (generating candidate programs). Interestingly, using a better LLM didn’t tend to improve performance — possibly related to the candidate programs being short, and the prompts being simple.

Kumar described the requirements for this approach to be problems where we can:
Both the cap set problem and the online bin packing problem meet these criteria (the former in a global sense, the latter conditional on a given distribution or dataset), and FunSearch was able to improve on existing results for these problems.
For more on FunSearch, see the Google DeepMind blog post describing the system.
Swarat Chaudhuri’s talk introduced some recent trends in LLM agents for formal theorem-proving, and described his lab’s approach which uses reinforcement learning aided by generative models and neuro-symbolic reasoning.

He gave an overview of his lab’s COPRA agent (arxiv), which combines GPT-4 generation with augmentation, backtracking, and a lemma database. He also gave a preview of an upcoming paper which makes use of cross-language learning (Coq/Lean/Isabelle) to increase dataset diversity (e.g. induction proofs are more common in Coq software verification proofs than in Lean).
Wenda Li’s talk started with some examples of the increasing interest in formal proofs from within the mathematics community, citing examples such as the Liquid Tensor Experiment and the Polynomial Freiman-Ruzsa conjecture.
While formal proofs have many advantages, manual formalisation is very labour-intensive and formal proofs are often less legible than informal proofs. Auto-(in)formalisation — being able to move from informal proofs to formal proofs and vice versa in an automated way — would mitigate these downsides.

Towards the end of the talk, Li covered the challenges of auto-formalisation, including the difficulty of mathematical formulation. As an example of this, he showed the IMO 2024 P5 — one of the problems AlphaProof failed to solve — and the formalised version (78 lines of Isabelle code) that took him over two hours to formulate.
Kun Zhang’s talk gave an overview of causal representation learning techniques — learning a causal representation of a system, often in the form of a directed causal graph —using examples from archeology and psychology.

Piotr Miłoś’s talk introduced hammers — tools that “integrate proof assistants with external automated-theorem-provers (ATPs) to aid in finding and applying premises and proof methods”. One such commonly-used tool in the Isabelle language is called Sledgehammer.

Miłoś’s lab developed two new methods:
Albert Q. Jiang’s talk started with a brief mention of two recent successes in automated mathematical reasoning using LLMs — Google DeepMind’s IMO silver medal and NuminaMath’s AIMO Progress Prize win.
However, he pointed out that LLMs are auto-regressive models — they generate new tokens based on past tokens — while many mathematical problems and datasets are structured in ways that are not well-suited to auto-regressive approaches.
For example, mathematicians generally write down and publish a final result which does not include their intermediate attempts or thinking process. After they build something, they tend to remove the scaffolding they used, making it hard to see how they arrived at their final result.
Jiang argued that synthetic data generation can be a key tool in mitigating these issues, and presented several techniques for generating both formal and informal data to this end.

One example of these techniques is what he calls rewriting: imagine a dataset of question-solution pairs where some written-up solutions start with an answer, followed by an explanation or proof. Rewriting the solution such that the explanation comes first and is followed by the answer makes it easier for auto-regressive models to learn from the data. This way it’s clear that the answer follows from the explanation, and it might be easier for these models to provide an answer once they have had the luxury of using multiple tokens’ compute to generate the explanation.
The Test of Time Award is given to an influential paper from 10 years ago.
This year’s Test of Time Award was won by ICML 2014’s DeCAF: A Deep Convolutional Activation Feature for Generic Visual Recognition and presented by Trevor Darrell, one of the authors.
Contextualising the paper, Darrell explained that in 2014 deep learning had limited adoption in the computer vision field, and while AlexNet had already shown success in object recognition many in the field were still skeptical about the use of convolutional neural nets (CNNs) for other computer vision tasks.

DeCAF provided more evidence of the promise of CNNs across many tasks, showing huge improvements on the state-of-the-art in domain adaptation benchmarks. It used an approach that we’re now very familiar with: freezing the weights of a pre-trained net (AlexNet), and attaching a smaller set of trainable parameters (in this case, a linear layer) that can be fine-tuned for specific tasks. Also described by Darrell as “the OG foundation model in vision”.
This is analogous to techniques such as LoRA which are used for fine-tuning LLMs today, and is very different to the prevailing paradigm of end-to-end learning from the time DeCAF was published.
Darrell credited the open-source code accompanying the paper with much of the traction it got in the community (alongside Caffe, a deep learning library which was later merged into PyTorch) — another thing that was not the norm at the time.
Another interesting comment was that some at the time felt like deep learning was “only for Google”, and required thousands of CPUs. It was quickly shown — through results like AlexNet and DeCAF — that just a few GPUs could be enough, allowing for increased uptake in deep learning.
Darrell left us by noting the similarity to today’s foundation model pre-training requiring (tens of) thousands of GPUs, and asking whether these might become more accessible over time too.
Chelsea Finn’s talk (link) shared insights on how to make progress in ML from a robotics perspective.

In particular, Finn addressed the issue that ML is data-hungry, and data can be expensive or difficult to obtain. She detailed three strategies she’s used in robotics, and how those can be applied in ML.
The main strategy she highlighted was the use of natural supervision — providing a trained model with limited natural language feedback that can be incorporated to improve future predictions.
In the Yell at your robot paper, Finn’s lab applied this to robotics, by building upon an existing approach which splits robot policies into a high-level (what to do) and low-level (how to do it) components, and uses natural language as an interface between the two components. Examples of high-level strategy command could be “move right” or “pick up the bag”.
Their innovation here was to freeze the low-level policy, and keep training the high-level policy — which can be done by providing text suggestions for a given previously-experienced state, and does not require additional robot demonstrations or interaction with a real-world environment.

In their CLARIFY paper, they applied a similar approach to image classification. Here a human observes a model’s failure modes, and can give targeted concept-level descriptions of scenarios where the model does not perform well. For example, a shape classifier which has incorrectly learnt to classify red shapes because of spurious correlations in the training data (most of the red shapes in training happened to be circles) can be given the feedback “red”. The CLARIFY procedure then fine-tunes the model on a dataset reweighted based on examples’ image-text similarity with the provided phrase (using CLIP), making it easier for the model to learn the correct rule for red shapes.
This seems to be a promising tool with many potential applications, and its use of global (concept-level) feedback contrasts the local (datapoint-level) feedback that is standard in reinforcement learning. The process of providing this feedback also seems more interesting (as well as easier/cheaper) than standard data-labeling tasks!
More data is out there, or easy to get, [we] just need algorithms that can use it well!
Two other approaches were covered — leveraging other data sources (e.g., using a pre-trained vision-to-text model to come up with robot strategies based on vision data), and incorporating data from test-time (in-context learning).
Papers mentioned:
A position paper in the reinforcement learning (RL) oral session made the argument for automatic environment shaping.
Environment shaping is standard practice in RL — a “necessary evil”. Without it, RL doesn’t work at all on some problems. It can take many forms — including reward shaping (changing the reward signal to encourage certain behaviours) and action space shaping (for example, allowing a robot controller to specify desired target positions rather than specifying individual torque values for each joint’s motor).

Environment shaping is usually done using heuristics and domain knowledge by either the creators of an environment, or researchers applying RL techniques to the environment. The authors take the position that automated environment shaping is an important research direction in RL, and proposed code-generation LLMs as a promising approach.
The project page, including a link to the full paper, can be found here.
One of the busiest posters in the morning session was for a paper which asks: what if we do next-token prediction with a simple linear model instead of a transformer?
Our results demonstrate that the power of today’s LLMs can be attributed, to a great extent, to the auto-regressive next-token training scheme, and not necessarily to a particular choice of architecture.

More photos of the poster session below.



Vukosi Marivate’s talk (link) covered a range of work — including research, development, and community-building — related to improving support for low-resource languages, with a particular focus on those spoken in the African continent.
He made it clear that creating chatbots in African languages wasn’t necessarily the right path — pointing out that for many of these low-resource languages, the availability of reliable and accurate digital dictionaries and thesauruses would already be a useful step.
Highlighted work included generating sentence-pair datasets between low-resource languages (bypassing the need to go via English for translation), as well as text augmentation tools and dataset curation work.

Links to mentioned resources:
Databricks still have some availability for their happy hour on Wednesday night (RSVP page). They’re also hiring — mainly looking for people to work on domain adaptation for LLMs.
If you’re noticing slightly less swag than expected, several companies’ marketing materials didn’t make it here due to the CrowdStrike/BSOD mess.

I’ve heard people finding it hard to get coffee outside of the conference coffee breaks… G-Research have great espresso in their booth!
A few more shots of the exhibition hall:


Lucia Magis-Weinberg’s talk (link) started with what we know about the impacts of digital technology on adolescents, with particular focus on her lab’s research in Latin America.
In addition to measurement, her lab designs interventions in the form of digital citizenship curricula that promote healthy digital habits in early adolescence.

She spoke about risks and concerns specific to AI, emphasising that the responsibility to build safe products for children lies with tech companies and developers (not with children/parents/educators), and highlighted the following resources:
Tuesday morning oral sessions included alignment, “positions on how we do ML research”, clustering, video, time series, and bio/chemistry applications.
I managed to catch most of the time series talks (link).
The Arrows of Time for Large Language Models (arxiv link) talk showed that, across many languages, LLMs are better at next-token-prediction in a forward direction than in a backward direction.
There were two talks showing new transformer-based approaches to time-series modelling.
MOIRAI (salesforce blog; arxiv) aims to be a universal time-series foundation model, through innovations including dynamic patch sizing and any-variate attention (a custom attention mechanism with several properties desirable for time-series).
By pre-training on datasets of various frequencies and with differing numbers of variables, MOIRAI aims to outperform other existing methods.

Alongside the paper, the MOIRAI team released the LOTSA (“Large-scale Open Time Series Archive”) dataset (Hugging Face link) containing a collection of open time-series datasets.
SAMformer (link to slides; arxiv) puts the lack of transformer success in time-series prediction down to the problem of sharpness — the presence of sharp local minima in the loss landscape leading to overfitting.

SAMformer fixes this by using Sharpness-Aware Minimisation (which smooths the loss landscape) to optimise a custom architecture combining channel-wise attention with a RevIN layer, and also reports an improvement over other transformer-based models while being on par with MOIRAI.
Soumith Chintala’s talk (link) — the first invited talk of the conference — explored the trade-offs between “open” and “closed” research. He examined the reasons why SOTA models/cutting-edge research became gradually more open between 2010 and 2020, after which it started becoming less open.
His view is that “full AI automation” is far away, and that AI research being open is preferable. Considering the various actors and their incentives, he stressed the importance of understanding why the trend away from openness has occurred, and what we can do to reverse it. He encouraged a focus on creating conditions for openness to thrive, rather than arguing about the benefits of open vs closed.

His key takeaways:
The main conference programme starts today, and kicks off with a few remarks from the conference chairs.
Some notable points:

The 10 best paper winners were announced, and can be found here.
The test of time award was won by DeCAF: A Deep Convolutional Activation Feature for Generic Visual Recognition (arxiv link). Trevor Darrell will present on Thursday.
Today ended with a welcome reception — food, drinks, and a DJ!

Tomorrow we’ll have the first invited talks, oral sessions, poster sessions, and official conference socials.
Adrián Arnaiz-Rodríguez and Ameya Velingker’s tutorial on Graph Learning (link) started with an introduction to graph learning, including a historical perspective.
They then covered basics of graph neural networks (GNNs) and trade-offs of GNNs vs graph transformers, as well as an overview of expressivity and generalisability (for more on this, see their poster in session 6 on Thursday) .

They introduced three core challenges faced by GNNs: under-reaching, over-smoothing, and over-squashing, and trade-offs between them controlled by GNN depth and sparsity techniques.
The tutorial finished with a panel discussion the future directions of graph learning. The tutorial site can be found here.
Margaux Zaffran and Aymeric Dieuleveut gave an overview of techniques (including split conformal prediction, full conformal prediction, and Jackknife+) for doing predictive uncertainty quantification with minimal assumptions (requiring exchangeable, but not necessarily independent and identically distributed, data).
In addition to the theoretical foundations, they also covered two case studies — regression on noisy medical images and time-series regression on energy prices — to show how these techniques could be applied.

The slides for the tutorial can be found here (large PDF, can take a while to load).
On Wednesday from 10am to 2pm (CST), Springer will host Chris Bishop, Director of Microsoft Research AI4Science and author of Deep Learning: Foundations and Concepts, for a book signing.

Also in the exhibition hall:
AI4Health is inviting PhD applications for their AI for Healthcare CDT programme with Imperial College London, and are open to collaboration with other organisations.

The American Association for the Advancement of Science (AAAS) is highlighting that their open access journals — in particular, health data science and intelligent computing — are open for submissions.

Translated provide $100k in grants annually, for research relevant to language services (details here).
First tutorial of the day (link), looking at efficient LLM serving from the perspective of both algorithmic innovations and system optimisations. Xupeng Miao gave a run-through of various techniques covered in his lab’s December 2023 survey paper, as well as some new ones.
")
It also featured some of their own research, including SpecInfer (tree-based speculative inference) and SpotServe (efficient and reliable LLM serving on pre-emptible cloud instances).
Sunday’s ICML Expo hosted various talks from sponsoring companies.
Google had a talk on AI for software development — featuring Smart Paste and AI tools for accelerating code migrations — as well as a talk on the practical and theoretical trade-offs of transformers vs graph neural networks (GNNs) for learning on graphs.
Amazon hosted talks on their autogluon AutoML package, automated evaluation of LLM outputs, and approaches for application performance monitoring.

Apple presented pfl-research, a simulation framework for federated learning research.
Tomorrow: tutorials, and the exhibition hall opens.
Official conference socials taking place at the conference venue are marked with an asterisk. Most others will require registration and will probably fill up quickly!
Sunday 21st
Monday 22nd
Tuesday 23rd
Wednesday 24th
Thursday 25th
Friday 26th
Something missing? Message me on the Whova conference app - search “Harald Carlens” under Attendees.
Summaries of industry lab papers and conference schedules can be found here:
We’re set for a mostly sunny and warm week in Vienna for ICML 2024.
Sunday is expo day, and registration is now open. Talks start this afternoon.

Registration is in Foyer A (Google Maps), by the entrance closest to the Messe-Prater underground station.

The conference venue is just around the corner from the Prater — a huge public park containing the sizeable Wurstelprater amusement park.

For occasional email updates from ML Contests with more content like this conference coverage and other events in competitive ML, subscribe to our mailing list.