Overview
The NeurIPS 2023 Competition Track hosted twenty official competitions, covering a diverse set of problems, with strong submissions across the board.
This article is a whistle-stop tour of those competitions with links to the relevant resources and winning solutions, where available. The summaries provided here are based mostly on interviews with the competition organisers, supplemented with materials from the competition workshops held at NeurIPS.
For the first time this year, organisers and winning participants of each competition will be invited to submit a paper to the Datasets and Benchmarks track in NeurIPS 2024. We’ll update this article to link to those papers when they’re published.
Special Topics in ML
Machine Unlearning
The Machine Unlearning Challenge, the first of its kind, tasked participants with taking a trained model and having it unlearn a subset of its training data (the “forget set”) while maintaining good performance on the rest of the data (the “retain set”) — all within a compute budget much smaller than that required to retrain the model from scratch on just the retain set.
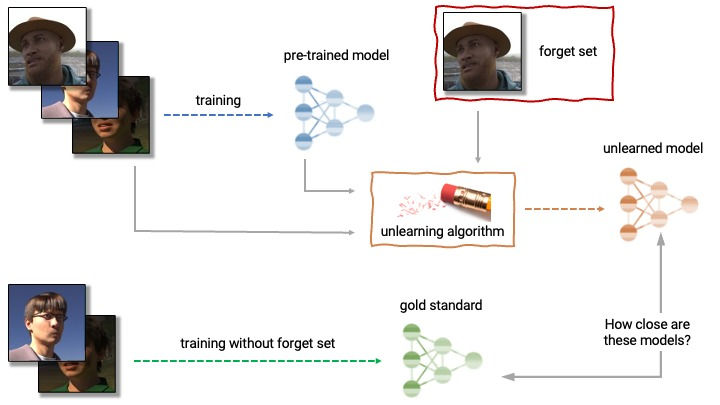
This challenge has obvious privacy-related applications, not least to support the “right to be forgotten” required by EU GDPR and other recent regulations.
Since the unlearning field is relatively young, this competition served to introduce a benchmark and iterate on an evaluation metric as much as it did to explore potential solutions. Unlike most competitions where participants submit predictions or an inference procedure, this competition required participants to submit a procedure for training an unlearned model from a provided model. Once submitted, a set of unlearned models would be trained and evaluated on their forgetting and retaining abilities.
The organisers mentioned that there was a lot of creativity in the solutions. While many participants used an “erase, then repair” approach in their solution, the way they achieved these steps differed, and some participants used totally unexpected methods. Many detailed solution write-ups are linked to from the competition leaderboard.
PPFL-DocVQA
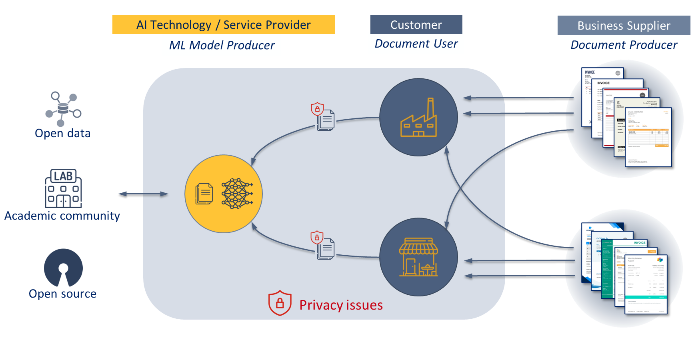
The Privacy Preserving Federated Learning Document VQA (PPFL-DocVQA) competition challenges participants to develop privacy-preserving solutions for fine-tuning multi-modal language models on distributed data.
This cross-disciplinary competition aims to bridge the document understanding community with the federated learning/privacy community, requiring participants to train document-understanding models in a federated way. The competition distributes sensitive data across 10 “clients”, and participants are required to train their models with limited bandwidth and privacy constraints between the clients.
In order to balance the desire for realism with the limited compute budgets of participants, participants can fine-tune a provided base model rather than needing to train from scratch.
Winning solutions made use of low-rank adaptation (LoRA) techniques for efficient fine-tuning, and are described on the results page.
This competition was organised by ELSA, the European Lighthouse on Secure and Safe AI, and the next iteration of the competition is expected to take place at ICDAR 2024.
Causal Structure Learning
The Causal Structure Learning from Event Sequences and Prior Knowledge challenge asks participants to identify the causal structure between alarm types in telecom networks.
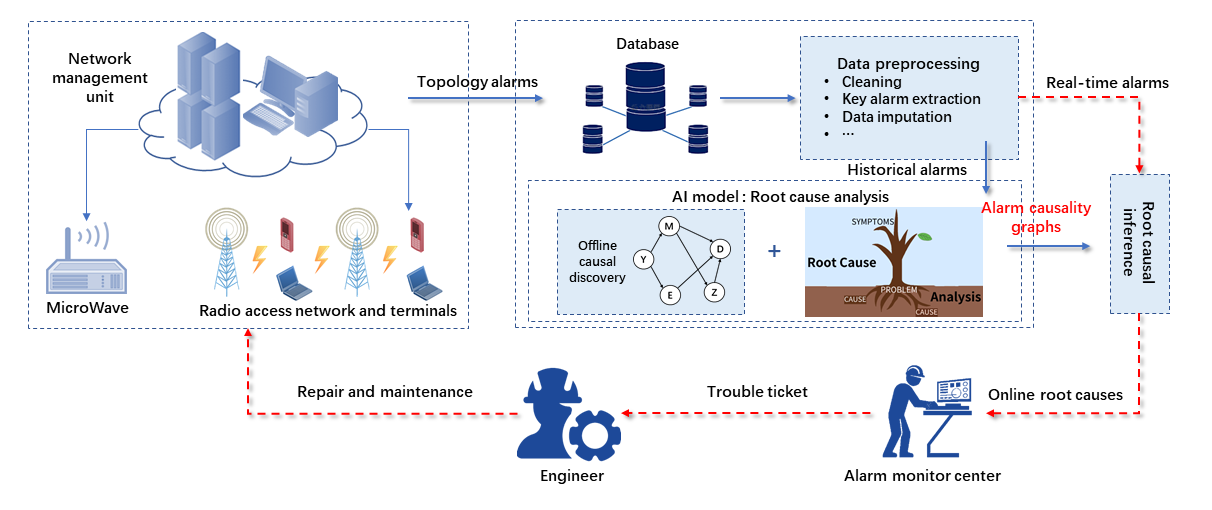
The leaderboard is available on CodaLab.
Big-ANN
The Big-ANN competition, sponsored by Microsoft, Pinecone, AWS and Zilliz, tests the ability of vector search algorithms to perform approximate-nearest-neighbour search in four specific tasks. Algorithms’ performance for each of the tasks is evaluated as either maximum throughput (queries/second) for a minimum recall threshold, or as maximum recall given some other constraints.
The four tasks include out-of-distribution, sparse, filtered, and streaming search. As one example, the filtered search track requires the ability to find the nearest neighbour within the subset of vectors with specific metadata tags. Performance was evaluated in a standardised compute environment.
This edition of the competition uses datasets of around 10M rows, reduced from NeurIPS 2021 version which used datasets with around 6B rows, in order to make the competition more accessible.
Source code for all competition entries is public, and each of the four tasks had a different winner — suggesting that participants successfully made use of the specifics of each task and tailored their algorithms to achieve better trade-offs.
The organisers mentioned that they were highly impressed with the performance of the submissions. In several of the tasks the winning solution improved upon the baseline by more than an order of magnitude, although they still don’t quite match the performance of state-of-the-art commercial closed-source solutions.
NLP and LLMs
LLM Efficiency
The LLM Efficiency Challenge asks the question: “Given 1 GPU and 24 hours, how well can you fine-tune a pre-trained base model?”
Participants were able to choose their base model from a list provided by organisers, and training data had to be taken from a set of datasets provided. Winning participants’ training runs were replicated by organisers after the competition to verify the results.
There were two tracks: one for data-centre GPUs (A100) and the other for retail GPUs (4090). Submissions were evaluated using a subset of the HELM benchmark.
Entries that performed well shared a few characteristics:
- Chosen base models were either Mistral-7B or Qwen-14B.
- Parameter-efficient fine-tuning techniques were used to fine-tune larger base models than the limited GPU memory would otherwise allow. QLoRA was one of the most commonly used techniques.
- Data filtering was key. Rather than trying to train on all the given data, selectively fine-tuning on subsets of the training data that were deemed to be high-quality and particularly relevant seemed to be crucial.
Winners’ code is available on the competition website.
LLM Trojan Detection
The Trojan Detection Challenge builds on last year’s NeurIPS 2022 Trojan Detection Challenge, and examines how we can detect hidden, undesirable behaviour in LLMs.
This can come in the form of Trojans (intentionally added to evade detection) or harmful behaviour (unintended, unwanted).
This competition featured separate tracks for trojan detection on large models and base models, as well as red teaming to elicit harmful behaviour on large models and base models.
Leaderboards are available on the competition website.
ML for Science
Weather4cast
The Weather4cast competition aims to build a benchmark for weather forecasting and nowcasting, as well as more generally to advance the state of the art for models that have to operate in highly unbalanced data scenarios and learn the characteristics of rare events.
This is the third such competition, a collaboration between the Spanish Meteorological Agency AEMET, the Silesian University of Technology SUT, and the IARAI/JKU in Austria,
Participants use satellite data to predict rainfall intensity as measured by radar. The Core track looks up to eight hours ahead, the Nowcasting track only four hours, and the Transfer Learning track’s test dataset includes three unseen regions as well as data for a year which isn’t in the training data.

As with some other competitions, competitors are required to open-source their code, and this year a team from Alibaba Cloud won the core and nowcasting tracks by building upon the winning solution from another group last year from Czech Technical University.
Solution write-ups and code are linked to from the Weather4cast website.
The ongoing nature of this competition allows organisers to iterate on solutions to thorny questions like “what is the right evaluation metric when predicting the magnitude of rare events?” in a practical setting.
MedFM
The Foundation Model Prompting for Medical Image Classification (MedFM) competition investigates the use of foundation models for medical diagnoses in three tasks: Thoracic Disease Screening (chest X-rays), Pathological Tumor Tissue Classification (colon tissue slices), and Lesion Detection (colonoscopy images).
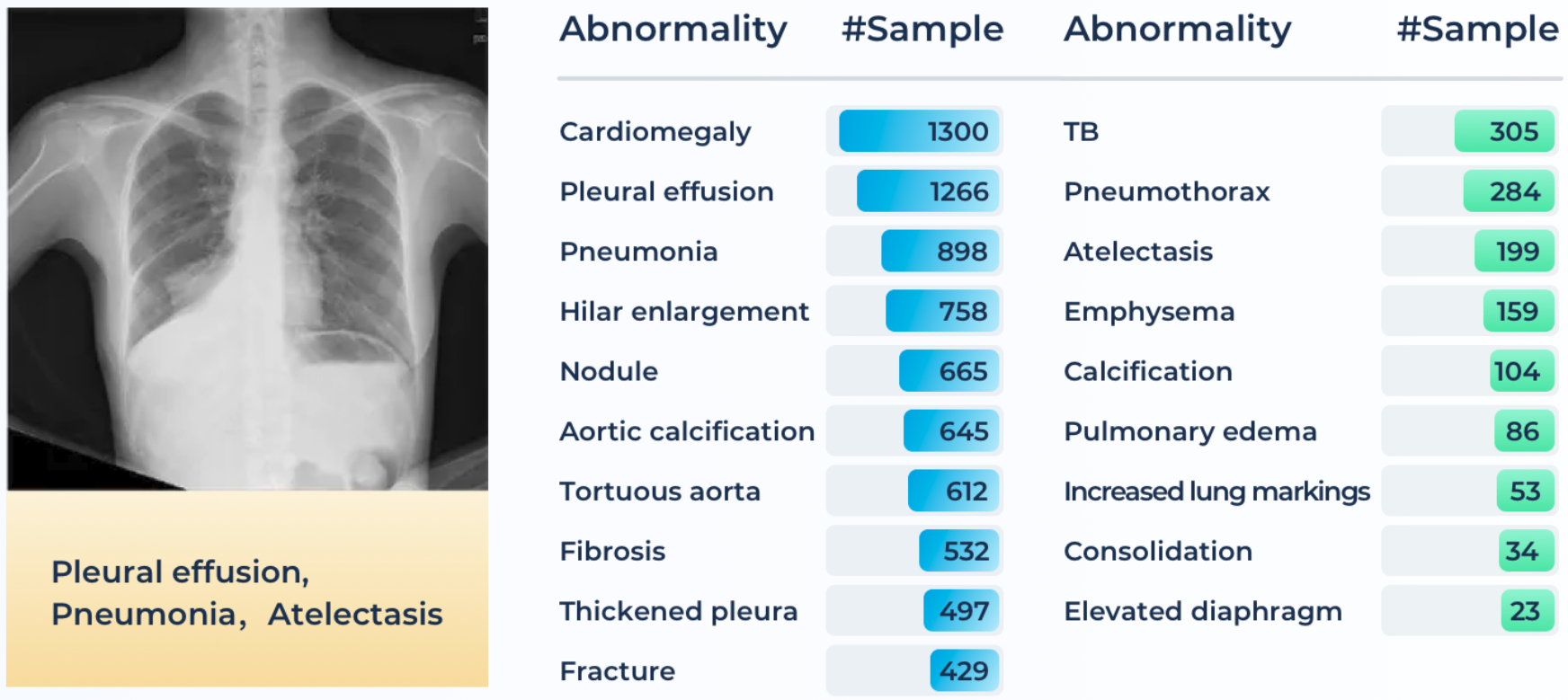
The competition leaderboard is available on Grand Challenge, alongside a new leaderboard for follow-on submissions.
Dynamic Sensorium
The Dynamic Sensorium competition introduces a new benchmark for predicting neuronal activity in mice, in response to visual stimuli. Building on last year’s Sensorium 2022 competition, which used images as input, this year’s competition uses video data.
The data used in the competition is a novel dataset, collected by the organisers, consisting of neuronal activity recordings for ten different mice in response to around 1,800 natural scene videos. The training set remains available for anyone to download.
The organisers set up a self-managed instance of CodaLab to host the leaderboard. This will remain open for submissions, allowing other researchers to benchmark their approaches relative to the competition entrants.
The main competition track used natural scene videos consistent with the training data, whereas the bonus track tested performance on out-of-domain stimuli using artificially generated videos.
Winners:
- Code for the first-placed solution from the main track, using a custom architecture based around spatial and temporal convolutions, is available on GitHub.
- Code for the third-placed solution, using a Vision Transformer, is available on GitHub too, alongside a paper describing the approach and a tweet thread by one of the authors.
- Second- and third-placed teams were both research groups. First place was a solo contribution by Ruslan Baikulov, a Kaggle competitions grandmaster.
Single-Cell Perturbation
The Single-Cell Perturbation Prediction competition is the third annual NeurIPS competition on open problems in single-cell analysis, sponsored by Cellarity, the Chan Zuckerberg Initiative, Yale, and HelmholtzZentrum Muenchen.
This edition challenged participants to predict how small molecules change gene expression in different cell types, which could have important applications in drug discovery and basic biology. The universe of potentially relevant chemical compounds is enormous, and leveraging representation learning for a smarter guided search could be a useful tool.
Half of the prize money was awarded for the best performing models, and the other half to the best write-ups.
The competition used a novel dataset collected by Cellarity. The private test set was composed of two cell types which were underrepresented in the training data, forcing successful participants to learn robust strategies and penalising those that overfit to the training set. This dynamic mimics the reality of this biological research, where researchers would want to use these models to predict the behaviour out-of-distribution.
Open Catalyst Challenge
The Open Catalyst Challenge aims to discover new, more efficient catalysts which can help improve energy storage and conversion and thereby help the transition to renewable energy.
This year’s challenge builds on previous editions at NeurIPS 2021 and NeurIPS 2022, and asks participants to predict the adsorption energy (global minimum binding energy) for a given adsorbate and a catalyst surface, a more general problem than the local minimisation one posed in previous challenges.
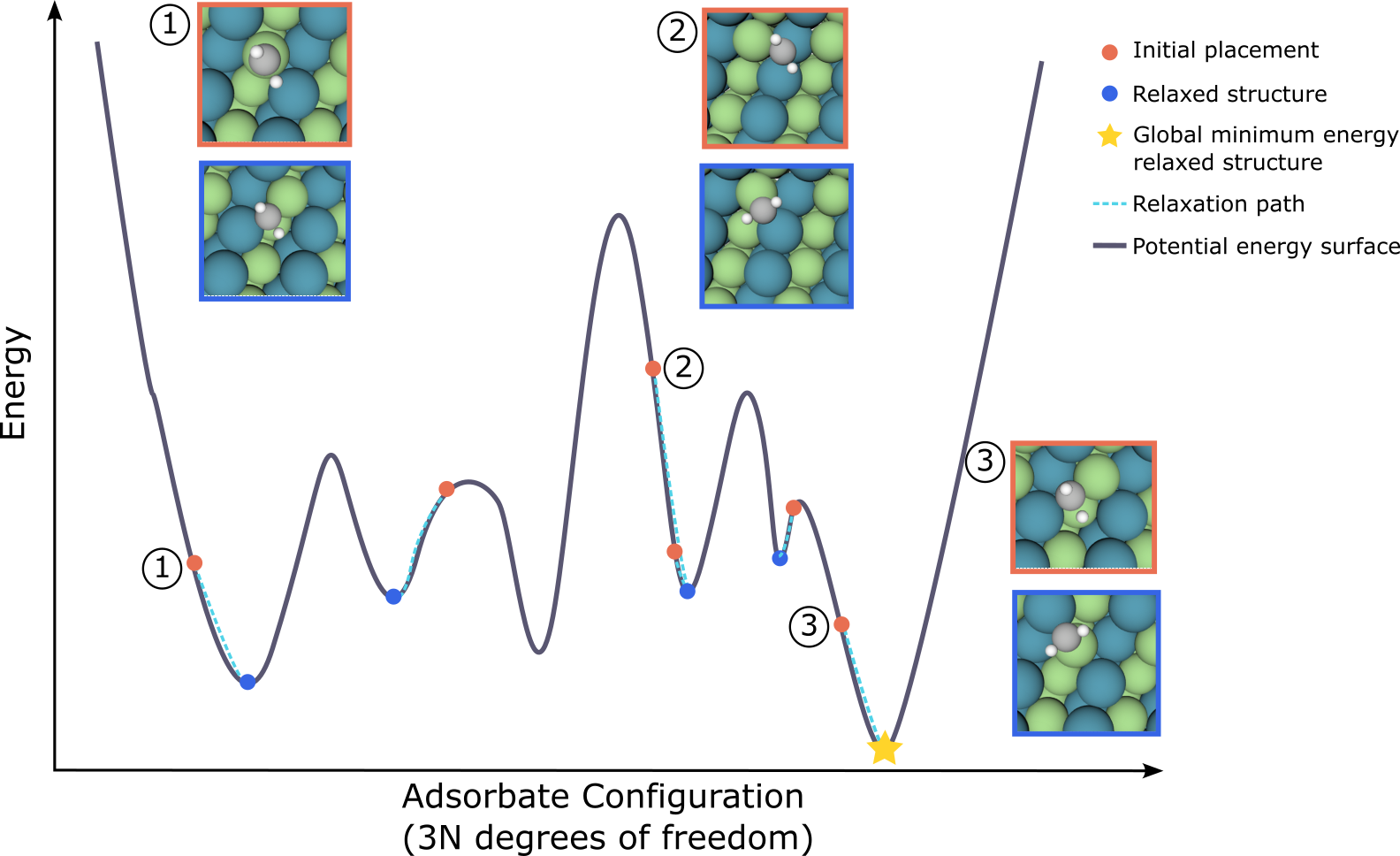
Results were presented at the AI for Scientific Discovery workshop, and the winners were team CausalAI from the University of Adelaide.
Multi-Agent Learning
Lux AI Season 2
Lux AI is a 2D grid-based PvP resource-gathering game built from the ground up for automated agents. Participants control robots and factories, with the aim to grow more lichen than their opponent.
The organisers want to combine the best of classical AI challenges designed for rules-based agents (BattleCode, Halite, Screeps) with modern AI research challenges where RL-based solutions are feasible (AI Habitat, Procgen, and MineRL).

The organisers plan to run another version of this competition in future, with even more of a focus on scalable benchmarks. By crowdsourcing strong human baselines and having an RL-friendly GPU-parellelisable environment, Lux AI could bridge the gap between games like Go/Atari (complex, but the human baselines don’t scale) and MineRL (interesting but computationally expensive) or XLand (interesting but closed-source). The Neural MMO environment is another project going in this direction.
The winning solutions for this edition of Lux AI were rule-based, and top competitors had prior experience in other games like MIT’s BattleCode and Screeps, where rule-based solutions also tend to dominate. Check out the leaderboard for more info on the solutions.
Neural MMO
Like Lux AI, The Neural MMO Challenge provides a complex game environment built from the ground up to be useful for AI research. Agents have access to ground-truth information about the game state, which can be accessed efficiently by slicing into a tensor.

The leaderboard is available on AIcrowd.
Melting Pot
The Melting Pot Contest studies cooperation in multi-agent settings using DeepMind’s Melting Pot Suite.

The leaderboard is available on AIcrowd
Environmental Challenges
CityLearn Challenge
This was the 4th edition of the CityLearn challenge, and the second one to be run on AIcrowd.
The organisers of the previous CityLearn challenges, Intelligent Environments Lab, were joined this year by the Energy Efficient Cities Initiative. In addition to the control track that made up previous editions, this year’s competition also has a forecasting track.
CityLearn is an interactive OpenAI gym-based simulation environment focused on demand-side energy management. Its goal is to help develop and test the technology that’s required for a successful transition to renewable energy, where energy sources can be more intermittent and more demand-side control is required.
This competition focused on domestic buildings:
- The forecasting track involved making predictions about building loads and solar generation up to 48 hours ahead.
- The control track involved developing a policy to manage heat pumps and energy storage systems (both batteries and domestic hot water), while optimising for thermal comfort, carbon emissions, energy efficiency, and robustness to power outages.
Hosting the competition on AIcrowd allowed the organisers to easily have a secondary leaderboard, after the competition ends, which they can use in their teaching. Last year’s secondary leaderboard was used at the IEL Climate Change AI Summer School.
Last year’s winning strategies are detailed in this PMLR paper. Interestingly, there were several significantly different approaches among the top solutions last year. One team used reinforcement learning, another used model-predictive control, and yet another used a basic predictive model to generate a forecast, and then solved an optimisation problem with respect to that forecast.
Anyone wanting to contribute to the CityLearn project can do so on GitHub.
Autonomous Systems
HomeRobot: OVVM
The HomeRobot Open Vocabulary Mobile Manipulation (OVVM) Challenge aims to create a platform that enables researchers to develop agents that can navigate unfamiliar environments, manipulate novel objects, and move away from closed object classes towards open-vocabulary natural language.

The challenge includes a simulation phase, followed by a physical robot phase. The leaderboard is available on EvalAI.
ROAD-R 2023
The ROAD-R competition applies a neuro-symbolic approach called learning with requirements to the practical problem of autonomous driving, and builds on previous ROAD and ROAD++ competitions at ICCV.
The underlying ROAD-R dataset is made up of videos annotated with road events, combined with a set of 243 logical constraints, such as “a traffic light cannot be red and green at the same time”. Prior research done by the organisers shows that “current state-of-the-art models often violate its logical constraints, and that it is possible to [make use of] them to create models that (i) have a better performance, and (ii) are guaranteed to be compliant with the requirements themselves”.
In the competition, participants needed to interpret video data and predict a combination of agent-action-location within bounding boxes, leveraging the logical constraints provided.
Due to the compute-intensive nature of the problem, the organisers arranged for $200 compute mini-grants to be made available to participants. Several participating teams mentioned that they would not have been able to take part without these mini-grants.
The winners’ code is public and can be found on the competition website.
Robot Air Hockey
The Robot Air Hockey Challenge was a collaboration between TU Darmstadt’s Intelligent Autonomous Systems lab and two labs within Huawei.
The goal was to explore strategies for safe robotic control — successfully playing air hockey within the constraints of the game rules, and without causing damage to the environment.
Two things make this problem particularly difficult from an ML point of view:
- Needing to learn the basics of safe robotic control — how to move the arm’s joints to keep the mallet moving in a plane on the table without smashing into the sides too hard — before even being able to think about game tactics or strategy.
- Chaotic interactions. When two round objects collide, a very small difference in the state (exact locations, velocities, or angular velocities) can result in a large difference in outcome (where the puck actually ends up going).

The competition leaderboard was based on simulated performance only (MuJoCo), but the most successful policies were also deployed on real robots after the challenge ended, with a wrapper around them to prevent dangerous behaviours.
Seven teams took part in the final stage, and the top 3 teams all used different strategies:
- Model-based end-to-end reinforcement learning
- Model-free reinforcement learning, with a structured policy
- Optimal control and imitation learning
The organisers were very impressed with the quality of submissions and hope to run the competition again next year.
MyoChallenge
The MyoChallenge requires participants to complete tasks using detailed musculoskeletal models in a simulation environment.
This is a cross-disciplinary effort, contributing to the understanding of human biomechanics by leveraging machine learning to build realistic simulations of human muscle movement.
Last year’s NeurIPS 2022 MyoChallenge had two tracks focused on object manipulation. This year’s challenge has one manipulation track (pick up an object; put it in a box) and one locomotion track (chase or evade an opponent).
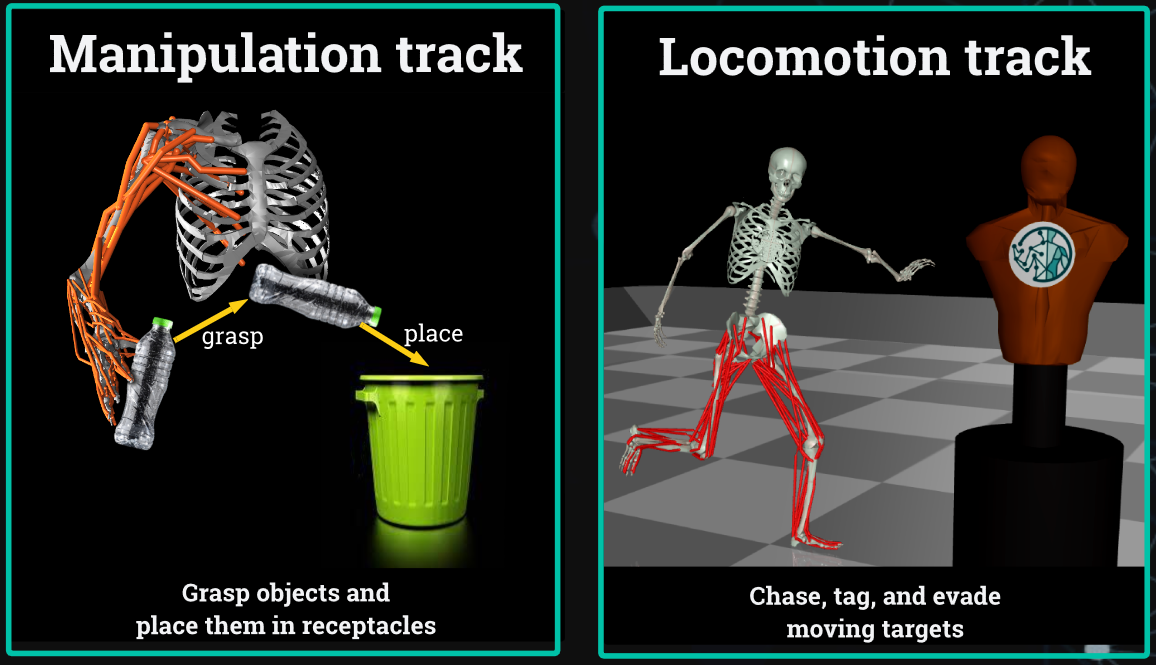
The competition is harder than it might look at first glance — the arm model for the manipulation task has 63 muscle-tendon units, and the leg model for locomotion has 80. Participants who performed well were creative with exploration strategies, as standard RL exploration strategies (e.g. adding random noise to the action space) tended not to be so effective in these problems.
The competition is implemented in the MyoSuite; a collection of musculoskeletal model environments/tasks simulated with the MuJoCo physics engine and wrapped in the OpenAI gym API.
TOTO Benchmark
The Train Offline Test Online (TOTO) Benchmark Challenge asks participants to train agents (in the MuJoCo simulator) and evaluate them (on a real robot) to scoop and pour containers of nuts, coffee beans, and other items.

The leaderboard is available on the competition website.
Acknowledgements
Thanks to all of the the competitions organisers and the NeurIPS Competition Track chairs Jake Albrecht, Marco Ciccone, and Tao Qin for bringing together such an exciting program of competitions at this year’s conference.
Contact details for each of the competition organisers are listed on the official NeurIPS 2023 Competition Track Program page.
For the rest of our NeurIPS 2023 coverage including daily summaries and overall highlights, go to our NeurIPS 2023 page.
For more on academic competitions: earlier this year we spent a week at ICRA in London, and wrote about their in-person robotics competitions.
NeurIPS 2023 is over, but we’ll be back.
For occasional email updates from ML Contests with more content like this conference coverage and other events in competitive ML, subscribe to our mailing list.