On Monday, NeurIPS hosted tutorials and affinity workshops. In this post we’ll cover a few general highlights and updates, followed by some more detail on the first invited talk and two of the tutorials we attended.
Awards
The conference awards were announced on Monday evening.
These two papers won the outstanding paper awards for the main track:
- Privacy Auditing with One (1) Training Run (Steinke et al.)
- Are Emergent Abilities of Large Language Models a Mirage (Schaeffer et al.)
And these were the outstanding papers for the datasets and benchmarks track:
- ClimSim: A large multi-scale dataset for hybrid physics-ML climate emulation (Yu et al.)
- DecodingTrust: A Comprehensive Assessment of Trustworthiness in GPT Models (Wang et al.)
The Test of Time Award (made out to a 10-year-old paper) this year went to Distributed Representations of Words and Phrases and their Compositionality by Tomas Mikolov, Ilya Sutskever, Kai Chen, Greg S. Corrado, and Jeff Dean.
NextGenAI: The Delusion of Scaling and the Future of Generative AI
The first of the invited talks, by Björn Ommer, was a fascinating tour of latent diffusion models with a focus on computer vision, weaving in elements of philosophy and art history. Björn’s lab developed Stable Diffusion, and the progress they’ve made even since releasing that is pretty incredible.
Themes throughout the talk included the necessity of democratising AI by enabling cutting-edge models to run on consumer hardware, and thinking beyond naive scaling — considering architecture improvements, and being aware of second-order changes rather than just projecting growth forward.
Useful/interesting links:
- Lab website
- Flow matching
- Review paper on state-of-the-art diffusion models for vision
- Retrieval-Augmented Diffusion Models
- iPOKE: a model for synthesising video based on a user “poking” a pixel
- Instant Lora Composition (coming soon)
Data-centric AI (Tutorial)
This was an interesting tutorial with lots of useful resources — notes, slides and links are available on the tutorial webpage.
The first two talks, by Mihaela van der Schaar and Nabeel Seedat, made the case for a data-centric approach to learning — as opposed to the more common model-centric approach. Their proposed data-centric approach puts the emphasis on iterating on the data, and getting a much deeper understanding of the data.
They introduced their data-centric AI checklist — DC-Check — and their library for data characterisation & Datagnosis. The latter can be incorporated in an existing training loop to give more insight into which data samples are learnable, important, ambiguous, or potentially mislabeled.

There was also discussion of using generative models to create synthetic data that can be used, for example, for debiasing (DECAF), or for various aspects of tabular data modelling (SynthCity).
This was followed by a talk by Isabelle Guyon, focused on competitions and benchmarks. She started off by discussing David Donoho’s recent Data Science at the Singularity paper, which posits that we are at a data-science-driven phase transition enabled by frictionless reproducibility through data sharing, code sharing, and competitive challenges in open services.
The rest of the talk explored how to design and organise successful competitive challenges, with a worked example on the open-source CodaBench platform. The content in this talk was a preview of a chapter she wrote for the upcoming book AI competitions and benchmarks: the science behind the contests, for which some chapters are already available as pre-prints (including this one which ML Contests contributed to!).
Governance & Accountability (Tutorial)
This tutorial was a great introduction to governance and accountability in ML. There were talks from Hoda Heidari and Emily Black, followed by a panel discussion.
Heida Hodari’s talk detailed the current state of governance, the key actors involved, and the legal frameworks in the US and Europe. A highlight for me was the overview of the EU AI Act and the recent US Executive Order on AI (14110).
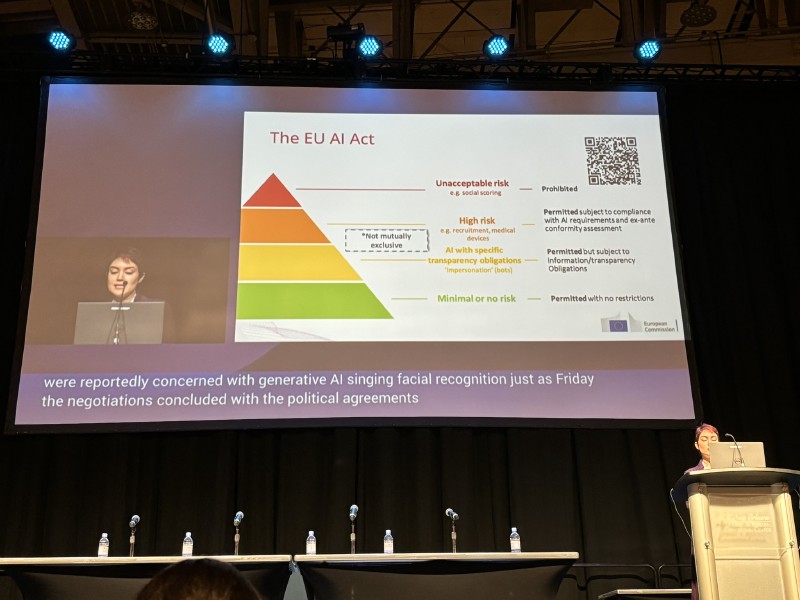
Emily Black’s talk explored an interesting case study on discriminatory algorithmic systems. She first introduced two legal doctrines relevant to algorithmic discrimination: disparate treatment and disparate impact.
One complication of the disparate impact doctrine is that it’s currently almost impossible to bring a successful legal case of algorithmic discrimination on the basis of it, since that requires a plaintiff (the person who brings the case) showing that a less discriminatory model would have done the job just as well.
As a tool for remedying this, Emily Black introduced the concept of model multiplicity: for any given prediction problem, there are almost always multiple possible models with equivalent performance. So why not choose from among these models with the goal of reducing discrimination and keeping performance unchanged? This could allow a re-interpretation of the disparate impact doctrine which puts the impetus on companies deploying models to proactively do the search for a ‘less discriminatory algorithm,’ rather than individuals.

Throughout the talks both speakers shared a wealth of interesting resources, including NIST’s AI risk management framework playbook, the Government of Canada’s Algorithmic Impact Assessment tool the pipeline-aware fairness wiki, GWU’s AI Litigation Database, and several OECD tools. Many more helpful resources are linked to from the tutorial website. I highly recommend checking it out.
The talks were followed by an interesting panel discussion, featuring panelists with significant legal, civil rights, and model evaluation expertise. At the end of the panel, the panelists were all asked to provide a recommended call-to-action for the audience wanting to contribute to governance.
The focus of their suggestions was: study practical problems, and bring them to the people who are trying to influence law and policy.
Other Tutorials
Some other tutorials that were particularly popular were those on Reconsidering Overfitting in the Age of Overparameterized Models (project page/ slides), Latent Diffusion Models (project page), and Application Development using LLMs (virtual conference page, requires NeurIPS registration).
Exhibit hall
The exhibit hall opened today. I’ll try to do some proper coverage of it later in the week, but today just a quick update based on a question on yesterday’s blog: Positron AI are building a Transformer-targeted inference appliance, with a dev workstation available today as part of an early access program and a server-level product planned for spring 2024. Their chips are less general-purpose than GPUs, but by specialising on Transformers and not catering for training it seems like they can get better inference speed/efficiency.
My understanding is that rather than having full support for general ML frameworks like PyTorch and TensorFlow, the initial release would support a number of pre-defined LLM architectures.


NeurIPS-adjacent News
After releasing a new mixture-of-experts model by tweeting a link to a torrent on Friday, Mistral AI have now announced API endpoints for these and other models, as well as confirmation that they have closed a new $400m+ funding round.
Tuesday is the start of the main conference program, which lasts until Thursday.
Read Tuesday’s blog here, and keep an eye on our NeurIPS 2023 page for more daily blogs and updates.